Importing & Remerging Text
Although older, Text Importing is covered in this tutorial
There are two kinds of text importing routines: Direct import, which creates a new databases and new additions to an existing database or Remerging, which alters items already in a database.
Direct Importing The process of importing text first requires you to prepare a tab separated text sheet(.tab, .txt) or comma separated (.csv) that has column headers that exactly match the V5 field structure. It is important they match case sensitivity as well. The text sheet cannot have carriage returns or trailing white spaces. For example:
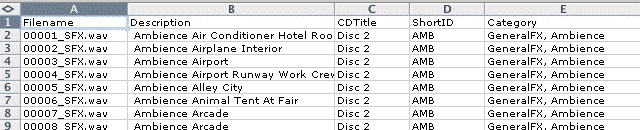
As a minimum, the text import must have a Filename column(used to link the data to an actual file on your drive), Description, Library and Manufacturer or Publisher.
Do not include hard attribute fields which are pulled from the file itself. This means: Duration, Time, Sample Rate, Bit depth, file format.
If you plan to use file path, it must be Posix formatted and exactly match your drive or it will not be found. If unsure, do not include file path and have the filename be the anchor by which text is metadata are resolved.
To import a properly formatted text sheet, use the import text option in the DATABASE menu:
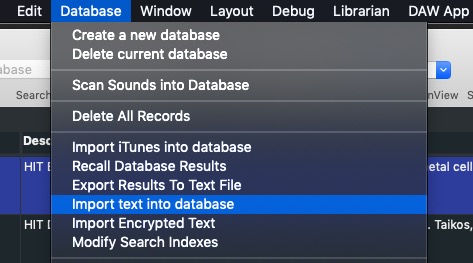
Soundminer will then prompt you for your text file and re-warn you of the formatting requirements.
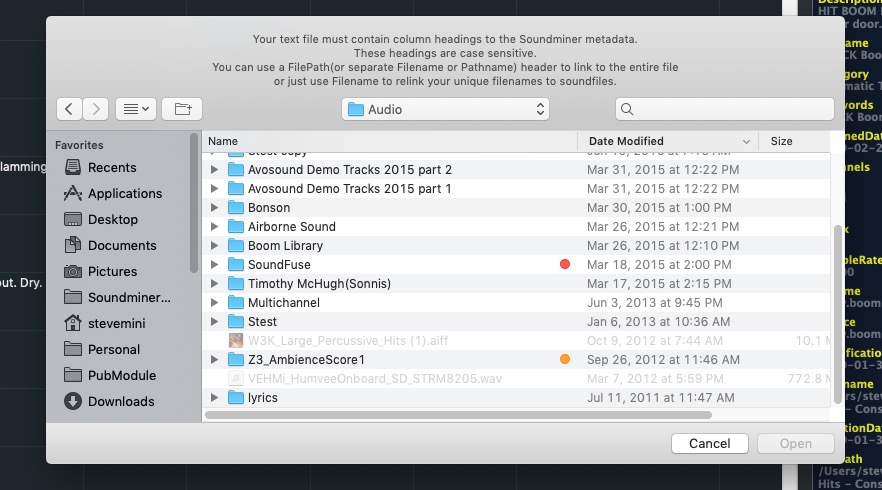
Once accepted it will prompt you to find the drive that contains the files so it can re-link them. Pick the top most folder containing all your files and the process will iterate over all files and build a database based on the successful matches with your text. When complete your database will be shown in the main browser and any errors will be listed in a log file printed in the same location as the application.
*****Linking the data from text and the files in Soundminer does not mean those files have been embedded with the data. To do this you must engage the embedding process from the contextual menus.
NOTE: Error log for Import text printed ~/Library/Logs
Import Encrypted text – In the past, we issued special text documents (like for Digital Juice SFX llibrary) that allows users to assign metadata to wave or aif files from DVDs. You would use this menu option for those cases. It requires one of our .mdem files. Contact support@soundminer.com if you need this library imported.
REMERGE Metadata This option is best used for times when you have scanned files with little or no metadata and have some of that data available elsewhere that you wish to merge. In these situations, the suggested process would require you to first select all the fields you wish to alter. In other words, use the Windows>Columns menu to check off all the fields that would apply to your import. This is important because the export process follows a ‘What you see is what you get’ approach. With that in mind, using the EXPORT RESULTS TO TEXT FILE Database Menu option, export that information along with a RECID (unique Identifier within that Database).
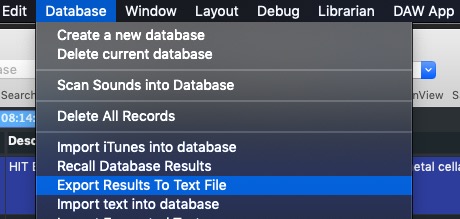
Name the file something appropriate and then you can open it in whatever text editor you prefer. That text sheet’s first column will have that database’s REC ID. Do not alter this as you work. By then copying from one text sheet to another, even in batches, you can fill up the metadata fields that were left open by the scanning process.
*Plenty if not more features for filling metadata already exist in v5Pro’s many metadata features, but we recognize some may feel more comfortable with their own text editor and have much of their data in similar but not the same format so it can relatively easily be copied into this exported text framework.
Here’s a tip, if your filenames don’t change and they are unique, delete the recid field after you export, that way filename becomes the unique “key” field, and that will be what soundminer uses to match back to the record in the database. Then the order can be anything and not tied intrinsically with the record id.
Once you have your files and your exported text sheet revised to your liking, use the REMERGE option to ‘marry’ that data with the original scan of the files. This will then update all the fields used to contain the remerged data. Be sure to embed after done and this will optimize the files for metadata use.
Remerge can be used anytime you wish to marry information that exists in some other format with your actual assets.
There are some crucial things to take into account when remerging… By default Soundminer export’s a recid and uses this when you remerge to match back up with the record. This means, that used this way, it should be the same database used that created the export. Otherwise, the recid’s won’t match up and you’ll have a real mess on your hands. Think of the recID as a unique field that Soundminer uses to get the record. So if the first column had a value of 2 it’ll get that record and then place the rest of the metadata overtop of the files in that row. If the recid’s mis-match, there will be utter chaos!
So what can you do if you don’t want to link on recid, or aren’t sure the values match up? Use a field like Filename(assuming all filenames are unique) as the first column. This way when Soundminer goes to remerge, it’ll now pull the first column in this case Filenameabc.wav from the text sheet, find that in the current database and then continue on.
**Reminder: The Apple OS does not inform us if an embedding routine is complete. IF a file has permissions blocked, it simply will not work and move onto the next file. To be sure embedding worked, you need to rescan your files back into V5 and verify. This is one of the reasons for the RAM DB.
Show Duplicate Filepath – this Database Menu item does a search for files with the same filepath.
When users scan in folders they have previously scanned and forget to check off the duplicate check in the Scanning preferences, they can add supplicates to their database. This menu options collects them and then allows you to remove them easily.
Show Records that Need Embedding(Dirty Records) – This Database Menu option notifies the user of all files that have had metadata changes made but have not embedded those changes back to the file.
Simply adding metadata to your V5 database does not write it back to the file. You must use one of the embedding menus to do this. It is easy to forget and this menu item collects all the files that have been modified for you to review.
© 2020 Soundminer Inc.